

Before AI Agents, There Were Algorithms
Why I Open Sourced Attribution

If you walk into any automotive conference this year, the air is thick with one word: Agents. Every vendor is trying to sell you an AI agent designed to automate your BDC, handle your service drive scheduling, or rewrite your vehicle descriptions.
Let’s be honest: digital marketing attribution isn’t the “hot topic” anymore. It’s not flashy, it’s not trending on LinkedIn, and it doesn’t get the main stage at NADA like generative AI does.
But just because the industry stopped talking about attribution doesn’t mean the problem went away. In fact, while everyone is distracted by the latest shiny AI hype cycle, this multi-million-dollar structural problem is quietly draining dealership bottom lines faster than ever.
I’ve spent years analyzing the intersection of retail operations and automotive technology, and I think it’s time we take a step back and look at a fundamental truth: Long before the industry got distracted by AI agents, we relied on algorithms. And long before we trusted flashy vendor dashboards, we relied on actual logic.
If you are an auto retailer trusting a vendor’s self-reported, aggregated dashboard to prove your media Return on Ad Spend (ROAS), you are grading their homework with their own answer key. The hype has changed, but the black box remains.
It’s time to stop guessing. We need to start asking for log-level data and keeping our partners honest. To prove it can be done, I have officially open-sourced my own data engineering framework on GitHub. Today, I’m breaking down exactly how it works and how you can use it to measure the effectiveness of your ad spend.
The Blind Spot: The 80% Invisible Buyer
Modern automotive digital publishers and aggregators love to claim credit for every unit that rolls off your lot. But look closely at how they track success: they still rely on fragile third-party cookies, digital tracking pixels, or form-fills (leads).
Here is the reality of the showroom floor that I see every single day: Over 80% of dealership walk-ins buy a vehicle without ever submitting a digital lead form. They shop online anonymously, look at a vehicle listing, and simply drive to the store.
Because of this digital “blind spot,” publishers are left guessing, and Dealers are left writing massive monthly advertising checks based on vanity metrics like “impressions” and “clicks” rather than cold, hard gross profit. The problem is old, but it’s still costing you money.
Moving From Guesswork to Deterministic Logic
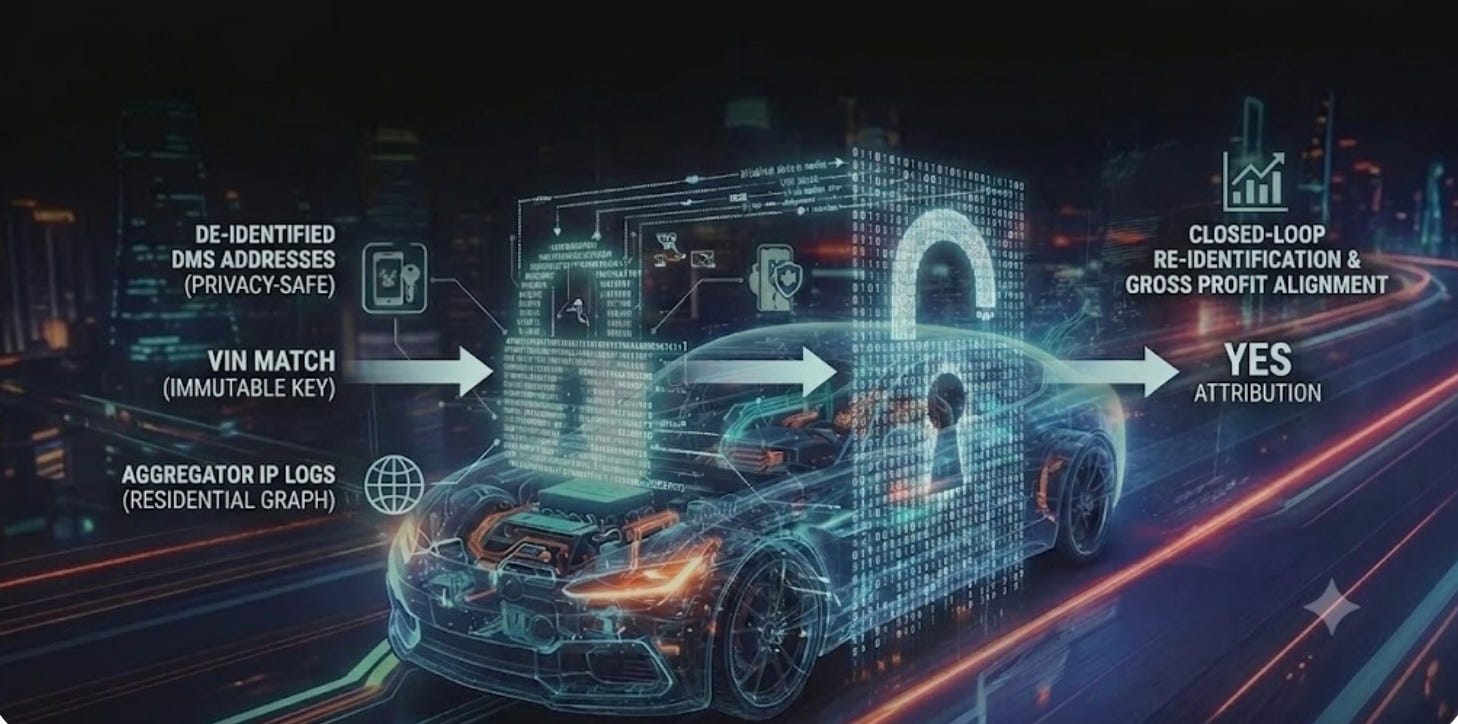
To bridge this gap, I designed a pipeline that shifts away from probabilistic tracking and moves toward a privacy-first, closed-loop identity resolution engine. The Python-based algorithm I’ve published bypasses the tracking pixel mess entirely by securely connecting offline Dealership Management System (DMS) sales data directly to a publisher’s raw digital footprint.
Here is how I engineered the mechanics to work step-by-step:
1. Temporal First-Party Onboarding
The pipeline ingests raw sales data from the DMS, filtering exclusively for sold vehicles within a strict historical lookback window (customizable to 30, 60, or 90 days depending on your reporting cycle).
2. Privacy-by-Design PII Isolation
To ensure absolute compliance with GLBA, CCPA, and data privacy regulations, the algorithm immediately strips out all direct customer PII (names, phone numbers, and emails). It isolates only two data points for the matching process: the physical delivery address and the vehicle’s unique identification number (VIN).
3. Log-Level Publisher Ingestion
The engine ingests raw IP log files from the publisher or aggregator site, which are mapped to physical households using a secure, residential identity graph.
4. Overcoming High-Density Node Duplication via the VIN
This is where my patented logic shines. In high-density residential areas (like apartment complexes or closely packed suburban neighborhoods), multiple households frequently share an internet service provider (ISP) network node or public IP footprint. In a traditional vendor dashboard, this causes massive false-positives—the vendor claims credit for five different households because they all sit on the same shared node.
My algorithm eliminates this by leveraging the immutability of the VIN. Because a physical vehicle can only be sold to one unique household, the unique VIN inherently overrides the shared network noise. The data natively and flawlessly resolves to the exact buying residence.
5. The Closed-Loop ROI Reconnect
Once a deterministic household match is verified, the algorithm appends the digital footprint back to the rich operational data of the original DMS file. The final export pairs the publisher visit directly with the vehicle model, sales date, and generated gross profit.
Gone but not forgotten.
Attribution might not be the sexiest topic in 2026, but profitability never goes out of style. As third-party cookies continue to depreciate and data regulations tighten, the dealerships that win will be the ones that own and audit their own data ledger.
You don’t need a bloated software suite or an expensive consultancy group to audit your ad spend. You just need pure, unmanipulated logic.
If you are a Dealer Principal, GM, or automotive data analyst who is ready to cut out the attribution noise and take absolute control of your first-party data, the codebase is public and ready for you to run.
I have made the core Python script and the architecture blueprint completely open-source. You can review the logic, plug in your mock data, and test the pipeline yourself.
👉 [Click Here to View My GitHub Repository and Patent Blueprint]
Have Fun: https://github.com/mrjonlamb/dms-identity-resolution-attribution/commit/d1e5363a9003804264157b1f7e59744226a20c95